Ran Wang, Xupeng Chen, Amirhossein Khalilian-Gourtani, Leyao Yu, Patricia Dugan, Daniel Friedman, Werner Doyle, Orrin Devinsky, Yao Wang, Adeen Flinker
https://www.pnas.org/doi/10.1073/pnas.2300255120
Abstract
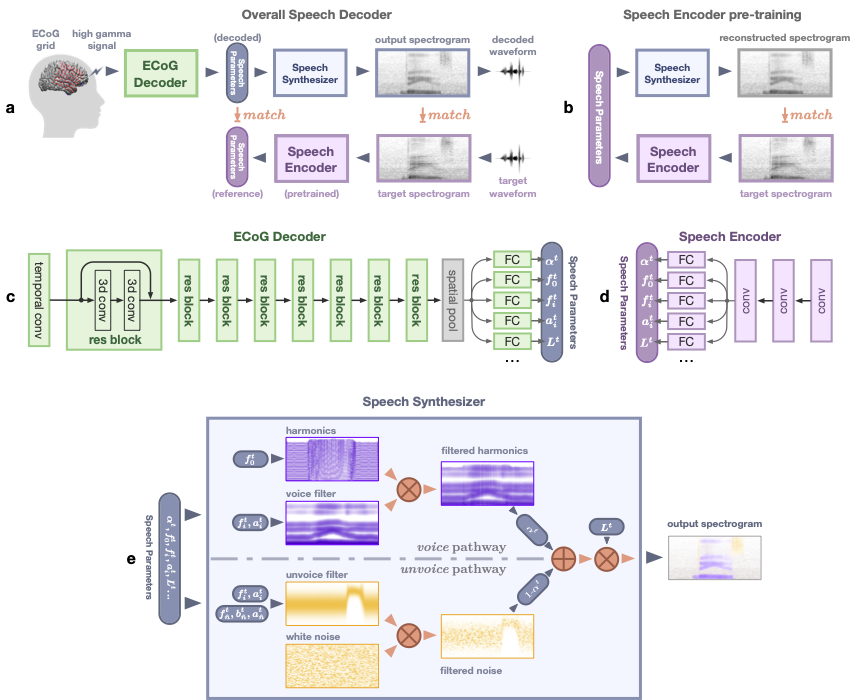
Speech production is a complex human function requiring continuous feedforward commands together with reafferent feedback processing. These processes are carried out by distinct frontal and temporal cortical networks, but the degree and timing of their recruitment and dynamics remain poorly understood. We present a deep learning architecture that translates neural signals recorded directly from the cortex to an interpretable representational space that can reconstruct speech. We leverage learned decoding networks to disentangle feedforward vs. feedback processing. Unlike prevailing models, we find a mixed cortical architecture in which frontal and temporal networks each process both feedforward and feedback information in tandem. We elucidate the timing of feedforward and feedback–related processing by quantifying the derived receptive fields. Our approach provides evidence for a surprisingly mixed cortical architecture of speech circuitry together with decoding advances that have important implications for neural prosthetics.
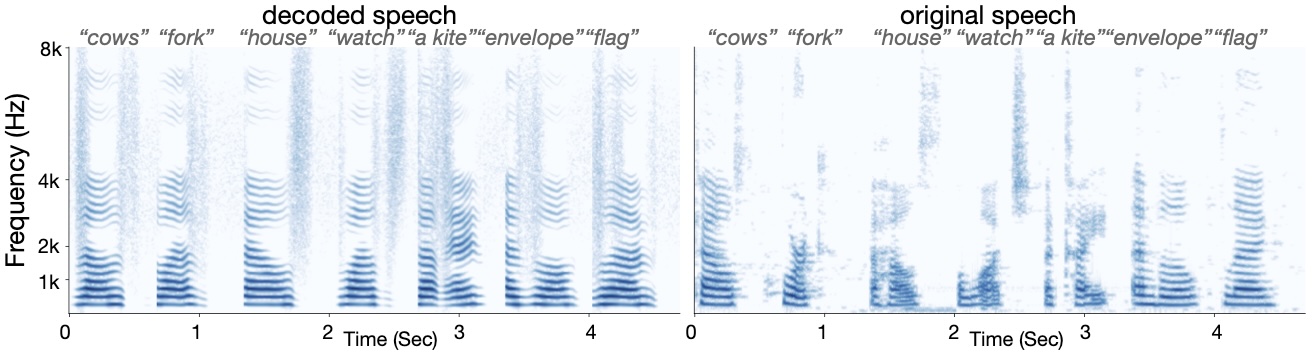
Decoded Samples
The samples of word waveform decoded from human brain activities. Each word is represented twice with real produced waveform played first followed by the neural decoded waveform.